本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
本文链接地址: https://www.huangyunkun.com/2016/12/06/apache-spark/
![]()
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架。最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。
Spark推出时的一个特点是快,对比的对象自然是Hadoop。
Hadoop这项大数据处理技术大概已有十年历史,而且被看做是首选的大数据集合处理的解决方案。MapReduce是一路计算的优秀解决方案,不过对于需要多路计算和算法的用例来说,并非十分高效。数据处理流程中的每一步都需要一个Map阶段和一个Reduce阶段,而且如果要利用这一解决方案,需要将所有用例都转换成MapReduce模式。
而Spark则允许程序开发者使用有向无环图开发复杂的多步数据管道。而且还支持跨有向无环图的内存数据共享,以便不同的作业可以共同处理同一个数据。
Spark的目的并不是代替Hadoop,相反Spark是可以运行于Hadoop之上的,包括了使用Hadoop文件系统,Yarn调度器等等。
Spark之上还有四个模块,分别对应了SQL,Streaming,ML还有Graph。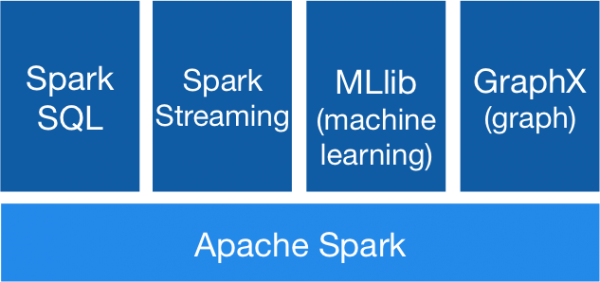
Spark近期的发力方向主要在于Machine Learning的Pipeline模式之上。
这种设计理念将机器学习统一抽象为由DataFrame,Transformer,Estimator和Parameter组成的Pipeline,并提供了大量可以重用的组件。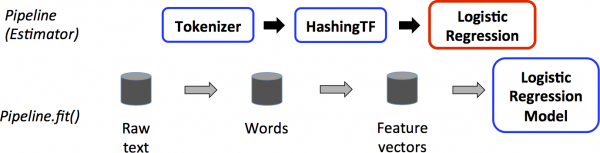
Spark提供了多种语言的API,你可以使用Scala,Java,Python或者R来开发你自己的应用。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
本文链接地址: https://www.huangyunkun.com/2016/12/06/apache-spark/