本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
本文链接地址: https://www.huangyunkun.com/2015/06/09/statistical-with-spark-dataframe/
DataFrame是R中一个基本结构,俗称数据框。其内部可以由多种数据类型,每一列是一个变量,每行是一个观测记录。在R中数据框是很通用的数据结构,它是一种特殊的列表对象。
在R中数据框对象包含了大量的基本数理统计运算,从简单的最大最小值和均值,再到协方差等等。
可以说数据框是了解一系列数据基本特性的快速方法,数据框的存在让R更加易用。
在Spark 1.3中新增了DataFrame,隶属于Spark-Sql模块下。
在即将到来的1.4版本中DataFrame的功能进一步扩充,而且在后续版本中会进一步提升。
具体可以参考
而1.4版本中主要增加的功能有:
- 随机数据生成
- 描述性统计
- 样本协方差和相关性
- 列联表
- 频繁项
随机数据生成
随机数据生成对于测试现有算法很有用,也可以用在随机算法的开发中。
SQLContext sqlContext =new SQLContext(sc);
DataFrame dataFrame = sqlContext.range(1,10);
DataFrame frame = dataFrame.select(functions.col("id"), functions.rand(10).alias("uniform"), functions.randn(25).alias("normal"));
frame.describe("uniform","normal").show();
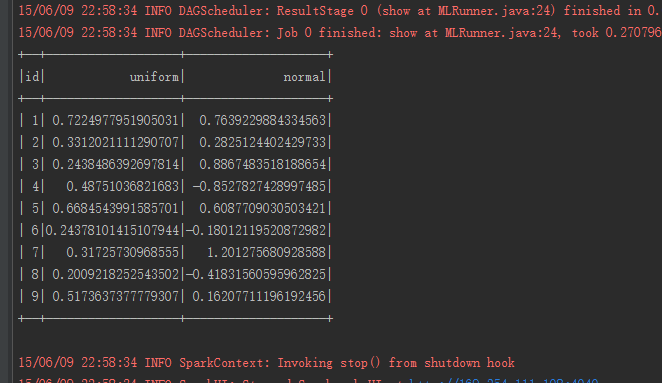
描述性统计
获得一些数据后需要做的第一步就是对数据整体有一个感知。描述性统计是指运用制表和分类,图形以及计算概括性数据来描述数据特征的各项活动。
描述性统计可以帮助我们了解到数据的大体分布和情况。
Spark中的描述统计提供了计数,均值,标准差,最大最小值等信息。
SQLContext sqlContext =new SQLContext(sc);
DataFrame dataFrame = sqlContext.range(1,10);
DataFrame frame = dataFrame.select(functions.col("id"), functions.rand(10).alias("uniform"), functions.randn(25).alias("normal"));
frame.describe().show();
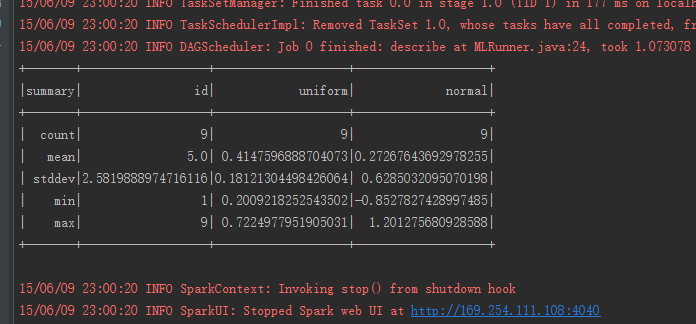
当然,可以看到直接调用describe会返回所有列的数据,如果只需要特定的数据,可以直接指定
|
|
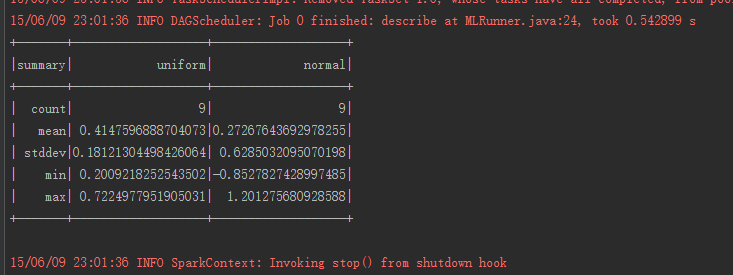
describe实质上返回的是另外一个数据框,其中具体计算的量由expr指定
val statistics = List[(String, Expression => Expression)](
"count" -> Count,
"mean" -> Average,
"stddev" -> stddevExpr,
"min" -> Min,
"max" -> Max)
样本协方差和相关性
在概率论和统计学中,协方差用于衡量两个变量的总体误差。
如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。
如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
如果两个量是统计独立的,那么二者之间的协方差就是0。
从理论上讲两列随机数的相关性应该为零,用Spark来计算一下。
SQLContext sqlContext =new SQLContext(sc);
DataFrame dataFrame = sqlContext.range(1,10);
DataFrame frame = dataFrame.select(functions.col("id"), functions.rand(10).alias("randX"), functions.randn(10).alias("randY"));
double cov= frame.stat().cov("randX","randY");
System.out.printf("cov: %s%n", cov);
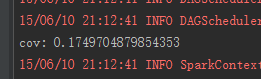
而相关性相对来说更容易理解,id是固定值,所以id和id自身是强相关的。
SQLContext sqlContext =new SQLContext(sc);
DataFrame dataFrame = sqlContext.range(1,10);
DataFrame frame = dataFrame.select(functions.col("id"), functions.rand(10).alias("randX"), functions.rand(10).alias("randY"));
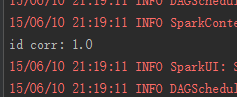
double id_corr = frame.stat().corr("id","id");
System.out.printf("id corr: %s%n", id_corr);
列联表和频繁项
从理论上讲这二者更像是一种操作而不是指标。
Spark数据框中提供的这两个功能更多的是为了快速的数据处理。
以列联表为例,
首先生成一个姓名和购买物品的两列表
SQLContext sqlContext =new SQLContext(sc);
String[] names = {
"Xiaoming",
"Xiaohong",
"Xiaogang"
};
String[] items = {
"milk",
"bread",
"butter",
"apples",
"oranges"
};
Random random =new Random();
List < Consumption > consumptions = Lists.newArrayList();
for (String name: names) {
for (int i =0; i <5; i++) {
consumptions.add(new Consumption(name, items[random.nextInt(items.length)]));
}
}
JavaRDD < Consumption > parallelize = sc.parallelize(consumptions);
DataFrame dataFrame = sqlContext.createDataFrame(parallelize, Consumption.class);
dataFrame.registerTempTable("consumption");
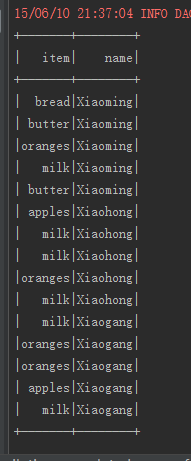
dataFrame.show()
然后联合
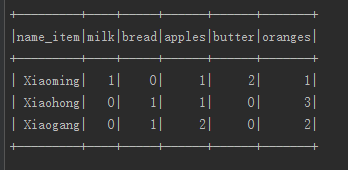
dataFrame.stat().crosstab("name","item").show();
写在最后
本文提到Spark对于数理统计的支持都在1.4版本中,目前还在rc4,可以通过快照版体验。
新的Spark MLlib包中也由于数据框的提升有了不少变动,特别是机器学习甬道的概念的融合,数据框将承担越来越多基本数据分析的功能。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
本文链接地址: https://www.huangyunkun.com/2015/06/09/statistical-with-spark-dataframe/