本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
Spark生态圈中有一个MLlib,其目标在于使机器学习更加简单和可扩展。
MLlib的开发非常活跃,其中添加新的算法和提升性能是一个主要的方向,而另一个方面是让MLlib更简单。
和Spark Core类似,MLlib提供了三种语言用API:Scala,Java和Python。用户可以根据文档和例子开始使用相应的功能,但是由于用户的技术和知识背景不同,学习曲线各不相同。为了让MLlib更好用,Spark 1.2开始引入了ML Pipeline API。
一个常见的机器学习流程包含了序列数据的预处理,特征提取,模型拟合和验证等。
以文本分类为例,包含了文本切割,文本清理,特征提取,训练分类模型和交叉检验。
虽然对于其中的每一个步,都有很多可以选用的第三方库来完成,但是将它们结合起来一起使用却不是那么简单。
很多库的API外观迥异,而且并没有为分布式数据处理提供支持。
Spark的ML Pipelines要做的就是从抽象层开始让机器学习更简单(不论是使用Spark以后的算法还是自己实现)。
数据抽象
在整体设计中,数据集的表现通过DataFrame来完成。DataFrame是Spark SQL中的组件。
除了单纯的数据源以外,还有一个或者多个转化器将数据转化后置入Spark甬道中。
转化器获取到输入数据并给出输出数据,输出数据又会成为下一个步骤的输入数据。
直接选用Spark SQL中的组件主要是考虑到了数据的输入输出,灵活的数据列类型操作和优化问题。
数据的输入输出是一个甬道的开始或者结束。
目前提供的输入输出包含了
- LabeledPoint (分类和回归)
- Rating (协同过滤)
- 等等
特征转化是一个甬道中的重要部分,比如将文本转为词序列,对词做TF-IDF变化等。

甬道
ML Pipelines相关内容都在spark.ml包下。
一个甬道包含了多个步骤,最基本的包含转化和评估。
转化就是上文提到的将文本转为词序列等等,评估更多的是训练对应的模型。
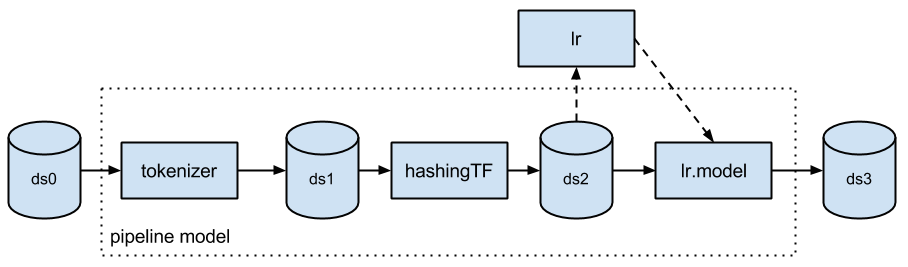
创建甬道:
Tokenizer tokenizer =new Tokenizer()
.setInputCol("text")
.setOutputCol("words");
HashingTF hashingTF =new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol())
.setOutputCol("features");
LogisticRegression lr =new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.01);
Pipeline pipeline =new Pipeline()
.setStages(new PipelineStage[] {tokenizer, hashingTF, lr});
然后评估模型
PipelineModel model = pipeline.fit(training);
结构如图:
主要实现了对应的接口,就可以很容易自定义转化和评估。
对应的例子可以参考JavaCrossValidatorExample。
变动
Spark 1.2开始引入了ML包,目前最新版本是1.3.1,1.4.0候选版本已经释出。
从1.2到1.3有一个比较主要大的变动是SchemaRDD被DataFrame替换,其他的主要是相关库的变动。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯