Spark的机器学习模块在2.x版本正式移动到ml包下,也就是说旧有的包只做维护不在添加新的功能。新的ml包中最大的改变就是使用用统一的工作流模型来囊括所有机器学习相关的东西。主要是以下三个大的目标:
- 线性可扩展
- 容错
- 内建所有的常用算法
我们的最终产物当然还是模型本身,也就是数学函数。工作流本身只是概念上的东西,并没有影响到本质。如果你喜欢,你也可以把工作流的所有东西拆开使用。
我们经常说学术界和工业界有很大的区别,比如你看到的ML Pipeline(文档或者文献)大部分长这个样子
 、
、
然而真实世界更为复杂,比如长这样

这之中的主要区别在于数据来源,你在文档中看到的更多是完美的数据输入,干净的数据,一次性的运行,而工业界的数据来源完全不能保证。
所以更多的时候我们把数据工作分为数据科学和数据工程。数据科学使用R或者Python去构建原型系统,而数据工程使用Java重写对应的实现。
Spark MLlib 2.x的一个重大改动就是对于模型序列化的优化,也就是说Python或者R输出的模型可以直接被Java载入。
ML Pipeline的另外一个好处就是隐藏了ML本身的代码,只要内建了足够的常用算法,或者模型能够不同语言通用,那么关于机器学习的核心代码其实是可以被Pipeline组合并隐藏掉具体的实现。
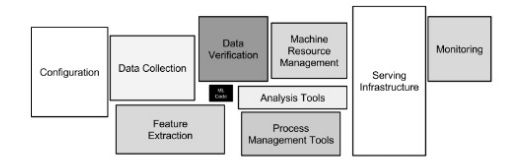
而工业界还有很多活需要干,比如配置,数据来源,可视化,应用健康监控等等。机器学习确实很酷,但是关注点是不同。
如果在两边在工作室都遵循工作流模型,并且尽可能重用内建的算法,那么渐渐的工程中就可以集中在数据抽取和最终的输出上。同时最开始输出的原型系统也能够和最终上线的产品系统有一个更高的一致性。
发表回复