本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
本文链接地址: https://www.huangyunkun.com/2016/07/26/docker-spark/
Spark模式是直接local直接开发的,也就是在SparkConf中直接设定为local[*]之类,就可以在本地启动Spark然后开始工作。
但是有时候还是希望将这些分开,也就是说有一个独立的Spark Master和一些Workers,本地开发,但是运行还是在简单的集群上。
因为需求很简单,所以直接自己写一个Dockerfile
FROM java:8
WORKDIR /opt
RUN wget -q http://apache.fayea.com/spark/spark-1.6.2/spark-1.6.2-bin-hadoop2.6.tgz -O spark.tgz
RUN tar xfz spark.tgz && mv spark-1.6.2-bin-hadoop2.6 spark
EXPOSE 8080 7077 6066
ENTRYPOINT ./spark/sbin/start-master.sh && ./spark/sbin/start-slave.sh spark://$(ip addr show eth0 | grep "inet\b" | awk '{print $2}' | cut -d/ -f1):7077 && tail -f /opt/spark/logs/*.out
这里使用的Spark 1.6.2配置hadoop 2.6。启动时首先运行master,然后在添加一个Worker在上面就行了。
这里暴露的是8080端口(网页UI),7077(服务端连接用)和6066端口(REST API)。
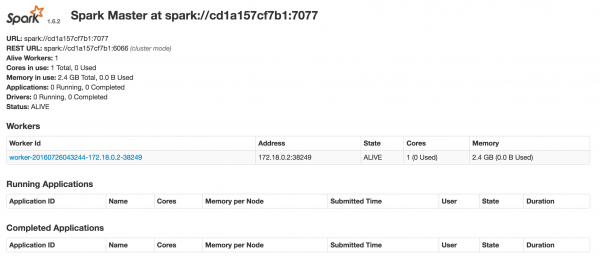
我直接在coreos上构建并且启动的。效果如下
然后本地来个简单的测试代码
SparkConf sparkConf = new SparkConf().setAppName("Test").setMaster("spark://172.17.8.101:7077");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);
System.out.println(distData.count());
Master的地址根据情况修改就行了,运行后应该能够看见输出中有一个5,而且在Spark UI中能够看到application信息。
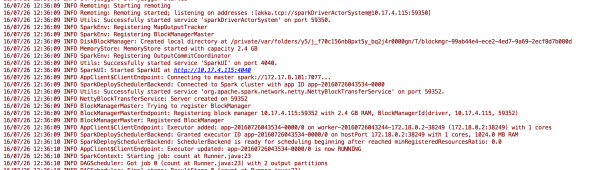
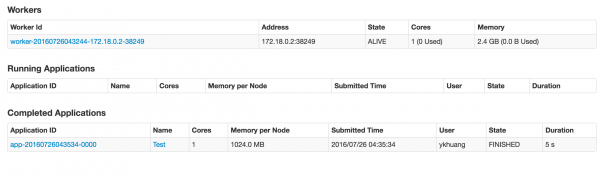
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
本文链接地址: https://www.huangyunkun.com/2016/07/26/docker-spark/