本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
本文链接地址: https://www.huangyunkun.com/2016/02/13/spark-datasets/
对于Spark的使用者来说,越简单易用的API越好。所以在原有的RDD之上,Spark陆续添加了DataFrames和Spark SQL。特别是DataFrames,对于小数据集的快速上手非常简单,其API也是从R中借鉴的,很有亲切感。当然在这之下,底层的实现还是RDD,只是对于使用者,抽象程度更高而已。
DataSets是为了解决类型安全和面向对象思维而添加的新API,包含在Spark 1.6中,其也是下个版本集中的方向。
DataSets并不是从关系型数据结构抽象出来的,所以它的API反而和RDD类似,比如
val lines = sqlContext.read.text("/wikipedia").as[String]
val words = lines
.flatMap(_.split(" "))
.filter(_ != "")
val counts = words
.groupBy(_.toLowerCase)
.count()
在直接使用的效率和资源消耗上要好一些(图来自DataBricks)
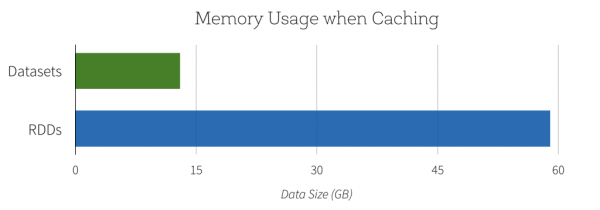
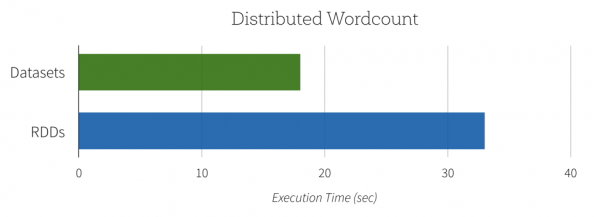
当然,另外一个增强面向对象的特性使用很简单, 主要基于Encoders
public class Person implements Serializable {
private String name;
get/set function{}
}
Dataset<Person> schools = context.read().json("/persons.json").as(Encoders.bean(Person.class));
参考资料
https://issues.apache.org/jira/browse/SPARK-9999
http://spark.apache.org/docs/latest/programming-guide.html
https://databricks.com/blog/2016/01/04/introducing-spark-datasets.html
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
本文链接地址: https://www.huangyunkun.com/2016/02/13/spark-datasets/