本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
本文链接地址: https://www.huangyunkun.com/2025/05/29/tensorflow-sleep-snoring-detection/
最近需要监测下睡眠情况,主要是分析打呼噜的情况。家里有一个小米摄像头,正好利用起来。
步骤也比较简单,睡觉前摄像头打开,然后随便对着墙(因为我们只要音频),第二天起床后把所有监控文件按照时间顺序合并,并转为wav文件。
我这里7个小时左右的音频,大小2.4GB。
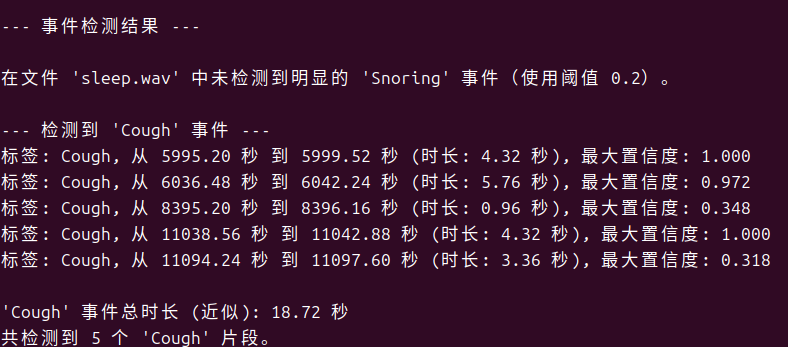
由于分析过程中发现有咳嗽的情况,又增加了咳嗽的监测。
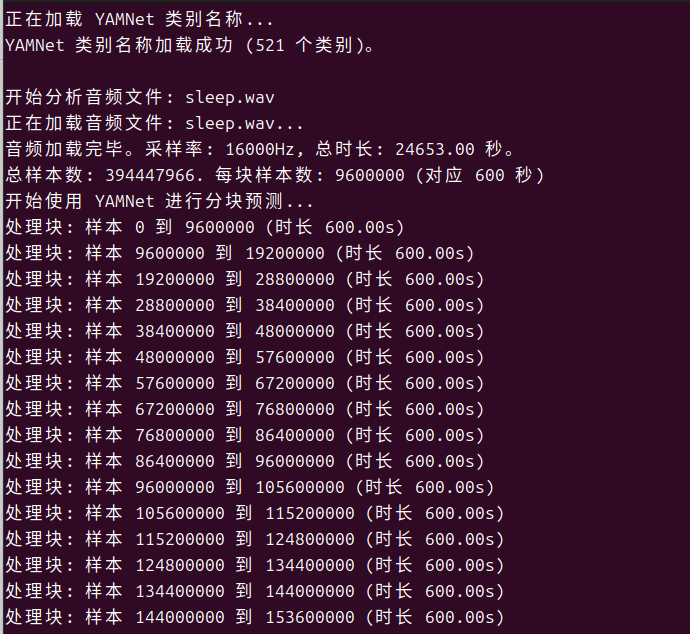
本来想一次性分析的,结果OOM了(我用的虚拟机,分配了48G),只有改成分段处理,内存消耗大概4GB。
完整代码
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
import librosa
import pandas as pd
import os
# import soundfile as sf # librosa.load is generally robust enough
# 可调整参数:
# audio_file_name: 在 main() 函数中修改为您的音频文件名。
# event_confidence_thresholds: 在 main() 函数中调整。这是一个字典,键是事件标签 (例如 "Snoring", "Cough"),
# 值是介于 0 和 1 之间的置信度阈值。较高的值会使得检测更严格,
# 减少误报,但可能漏掉不典型的或轻微的声音。
# 建议从 Snoring: 0.15-0.25, Cough: 0.2-0.3 开始尝试。
# event_merge_threshold: 在 main() 函数中调整。如果同一类型的两个检测事件的结束和开始时间间隔
# 小于此阈值(秒),它们将被合并。
# CHUNK_DURATION_SEC: 在 predict_audio_events 中调整,处理长音频时的分块大小(秒)。
def load_yamnet_model_and_class_names():
"""加载 YAMNet 模型和类别名称"""
try:
print("正在加载 YAMNet 模型...")
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
print("YAMNet 模型加载成功。")
print("正在加载 YAMNet 类别名称...")
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names_df = pd.read_csv(class_map_path)
class_names = class_names_df['display_name'].tolist()
print(f"YAMNet 类别名称加载成功 ({len(class_names)} 个类别)。")
return yamnet_model, class_names
except Exception as e:
print(f"加载 YAMNet 模型或类别名称时出错: {e}")
print("请确保您的网络连接正常,并且 TensorFlow Hub 可以访问。")
print("如果问题持续,您可能需要检查 TensorFlow 和 TensorFlow Hub 的版本兼容性。")
return None, None
def merge_overlapping_events(events, time_threshold=0.5):
"""
合并时间上重叠或非常接近的事件。
Args:
events (list): 事件字典列表,每个字典包含 "start_time_seconds",
"end_time_seconds", "confidence", "label"。
time_threshold (float): 合并事件的最大时间间隔(秒)。
Returns:
list: 合并后的事件列表。
"""
if not events:
return []
events.sort(key=lambda x: x["start_time_seconds"])
merged = []
current_event = events[0].copy()
for i in range(1, len(events)):
next_event = events[i]
if next_event["start_time_seconds"] <= current_event["end_time_seconds"] + time_threshold:
current_event["end_time_seconds"] = max(current_event["end_time_seconds"], next_event["end_time_seconds"])
current_event["confidence"] = max(current_event["confidence"], next_event["confidence"])
else:
merged.append(current_event)
current_event = next_event.copy()
merged.append(current_event)
return merged
def predict_audio_events(audio_path, model, class_names_list,
target_labels_with_thresholds,
merge_time_threshold=0.5,
default_confidence_threshold=0.1,
chunk_duration_sec=60): # <<< 新增:分块处理时长(秒)
"""
使用 YAMNet 检测音频文件中指定类型的声音事件,支持长音频分块处理。
"""
if not model or not class_names_list:
print("错误:YAMNet 模型或类别列表未加载。")
return {label: [] for label in target_labels_with_thresholds}
if not os.path.exists(audio_path):
print(f"错误:音频文件未找到: {audio_path}")
return {label: [] for label in target_labels_with_thresholds}
label_indices = {}
for target_label in target_labels_with_thresholds.keys():
try:
label_indices[target_label] = class_names_list.index(target_label)
except ValueError:
print(f"警告:标签 '{target_label}' 在 YAMNet 类别名称中未找到。将跳过此标签。")
if not label_indices:
print("错误:没有可用的有效目标标签。")
return {label: [] for label in target_labels_with_thresholds}
print(f"正在加载音频文件: {audio_path}...")
try:
# YAMNet 需要 16kHz 单声道,float32 范围 [-1.0, 1.0]
# librosa.load 会自动重采样到16kHz
full_waveform, sr = librosa.load(audio_path, sr=16000, mono=True)
full_waveform = full_waveform.astype(np.float32)
if np.max(np.abs(full_waveform)) > 1.0:
full_waveform /= np.max(np.abs(full_waveform))
except Exception as e:
print(f"加载或转换音频文件时出错: {e}")
return {label: [] for label in target_labels_with_thresholds}
if full_waveform.size == 0:
print("错误:加载的音频波形为空。")
return {label: [] for label in target_labels_with_thresholds}
print(f"音频加载完毕。采样率: {sr}Hz, 总时长: {len(full_waveform)/sr:.2f} 秒。")
frame_hop_seconds = 0.48 # YAMNet 帧移
frame_window_seconds = 0.96 # YAMNet 窗长
# 分块处理
samples_per_chunk = int(chunk_duration_sec * sr)
num_samples_total = len(full_waveform)
all_scores_list = []
print(f"总样本数: {num_samples_total}. 每块样本数: {samples_per_chunk} (对应 {chunk_duration_sec} 秒)")
print("开始使用 YAMNet 进行分块预测...")
for i in range(0, num_samples_total, samples_per_chunk):
chunk_start_sample = i
chunk_end_sample = min(i + samples_per_chunk, num_samples_total)
chunk_waveform = full_waveform[chunk_start_sample:chunk_end_sample]
if len(chunk_waveform) < int(frame_window_seconds * sr) : # YAMNet需要至少一个完整窗口的音频
if num_samples_total < int(frame_window_seconds * sr) and i == 0: # 音频本身就太短
print(f"音频片段 (从样本 {chunk_start_sample}) 太短 ({len(chunk_waveform)/sr:.2f}s),无法处理。至少需要 {frame_window_seconds:.2f}s。")
elif len(chunk_waveform) > 0 : # 最后一个块可能很短,但仍尝试处理
print(f"处理最后一个短音频片段 (从样本 {chunk_start_sample}, 时长 {len(chunk_waveform)/sr:.2f}s)...")
else: # 空块,跳过
continue
else:
print(f"处理块: 样本 {chunk_start_sample} 到 {chunk_end_sample} (时长 {len(chunk_waveform)/sr:.2f}s)")
if len(chunk_waveform) > 0:
# YAMNet 模型直接处理波形
# scores的形状是 (num_frames, num_classes)
scores_chunk, _, _ = model(chunk_waveform)
all_scores_list.append(scores_chunk.numpy())
else:
print(f"跳过空音频块 (样本 {chunk_start_sample} 到 {chunk_end_sample})")
if not all_scores_list:
print("警告:没有生成任何分数。音频可能太短或在分块后为空。")
return {label: [] for label in label_indices.keys()}
print("所有块处理完毕,正在合并分数...")
scores_np = np.concatenate(all_scores_list, axis=0)
print(f"合并后的总帧数: {scores_np.shape[0]}")
all_detected_events = {label: [] for label in label_indices.keys()}
print(f"根据合并后的分数处理 {scores_np.shape[0]} 个音频帧...")
for i, frame_scores in enumerate(scores_np):
for target_label, class_index in label_indices.items():
score = frame_scores[class_index]
confidence_threshold = target_labels_with_thresholds.get(target_label, default_confidence_threshold)
if score >= confidence_threshold:
# 时间戳是相对于整个音频的开始
start_time = i * frame_hop_seconds
end_time = start_time + frame_window_seconds
all_detected_events[target_label].append({
"start_time_seconds": round(start_time, 2),
"end_time_seconds": round(end_time, 2),
"confidence": round(float(score), 3),
"label": target_label
})
merged_results = {}
for target_label, events in all_detected_events.items():
if events:
print(f"初步检测到 {len(events)} 个可能的 '{target_label}' 事件(合并前)。")
print(f"正在为 '{target_label}' 合并时间间隔小于 {merge_time_threshold} 秒的事件...")
merged_events = merge_overlapping_events(events, time_threshold=merge_time_threshold)
print(f"合并后得到 {len(merged_events)} 个 '{target_label}' 事件。")
merged_results[target_label] = merged_events
else:
merged_results[target_label] = []
print(f"未初步检测到 '{target_label}' 事件。")
return merged_results
def main():
audio_file_name = "sleep.wav" # <<--- 将此替换为您的文件名
yamnet_model, class_names = load_yamnet_model_and_class_names()
if yamnet_model and class_names:
print(f"\n开始分析音频文件: {audio_file_name}")
target_events_with_thresholds = {
"Snoring": 0.1,
"Cough": 0.25
}
event_merge_threshold = 1.0
audio_processing_chunk_seconds = 600 # 处理音频的块大小,单位秒
detected_events_map = predict_audio_events(
audio_file_name,
yamnet_model,
class_names,
target_labels_with_thresholds=target_events_with_thresholds,
merge_time_threshold=event_merge_threshold,
default_confidence_threshold=0.15,
chunk_duration_sec=audio_processing_chunk_seconds # 传递块大小
)
print("\n--- 事件检测结果 ---")
any_event_detected = False
for label, events in detected_events_map.items():
if events:
any_event_detected = True
print(f"\n--- 检测到 '{label}' 事件 ---")
total_event_duration = 0
for event in events:
duration = event['end_time_seconds'] - event['start_time_seconds']
total_event_duration += duration
print(
f"标签: {event['label']}, 从 {event['start_time_seconds']:.2f} 秒 "
f"到 {event['end_time_seconds']:.2f} 秒 "
f"(时长: {duration:.2f} 秒), "
f"最大置信度: {event['confidence']:.3f}"
)
print(f"\n'{label}' 事件总时长 (近似): {total_event_duration:.2f} 秒")
print(f"共检测到 {len(events)} 个 '{label}' 片段。")
else:
confidence_val = target_events_with_thresholds.get(label)
if confidence_val is None: # Should not happen if label is in target_events_with_thresholds
confidence_val_str = f"默认({0.15})" # Assuming 0.15 is the default_confidence_threshold
else:
confidence_val_str = str(confidence_val)
print(f"\n在文件 '{audio_file_name}' 中未检测到明显的 '{label}' 事件(使用阈值 {confidence_val_str})。")
if not any_event_detected:
print(f"\n在文件 '{audio_file_name}' 中未检测到任何指定的目标事件。")
print("您可以尝试调整 `target_events_with_thresholds` 中的阈值以检测更细微的声音,但这可能会增加误报。")
else:
print("由于模型或类别名称加载失败,无法进行事件检测。")
if __name__ == "__main__":
main()检测效果
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载自夜明的孤行灯
本文链接地址: https://www.huangyunkun.com/2025/05/29/tensorflow-sleep-snoring-detection/